








数据解决方案自动化供应商 Varigence 如何使用图表来增强数据优势。
创建数据解决方案(例如数据仓库)通常意味着将来自各种不同系统的数据集成为公司业务及其数据的整体表示。数据解决方案本身就很复杂。为了产生有意义的结果,数据通常要经过分层解决方案架构中定义的许多小“步骤”。
通过这些数据物流过程(传统上称为提取、转换和加载(“ETL”)),数据逐渐转变为其目标解释,即消费者可以从中访问用于各种用例的数据的预期(数据)模型。
数据解决方案很容易包含数千个数据物流流程,每个流程都需要开发、分类、维护和监控。手动交付和管理如此多的数据物流流程可能非常耗时。
不仅仅是可视化
数据自动化的基础是一个或多个数据集之间的“源到目标”映射概念。这种“映射”关系可以作为各种数据基础设施的数据物流流程生成,例如数据库视图、存储过程、Databricks 笔记本、Azure 数据工厂 (ADF) 管道、SQL Server Integration Services
(SSIS) 包和各种脚本语言。为了了解数据流,能够以有意义的方式显示源数据集和目标数据集之间的沿袭是一项关键要求。
然而,作为设计和开发产品,不仅要可视化数据及其关系的定义,而且还要定义它们,这一点很重要。Varigence 需要一个图形用户界面,让用户能够以各种方式与设计进行交互。这就是yFiles 的作用所在。
交互式图表
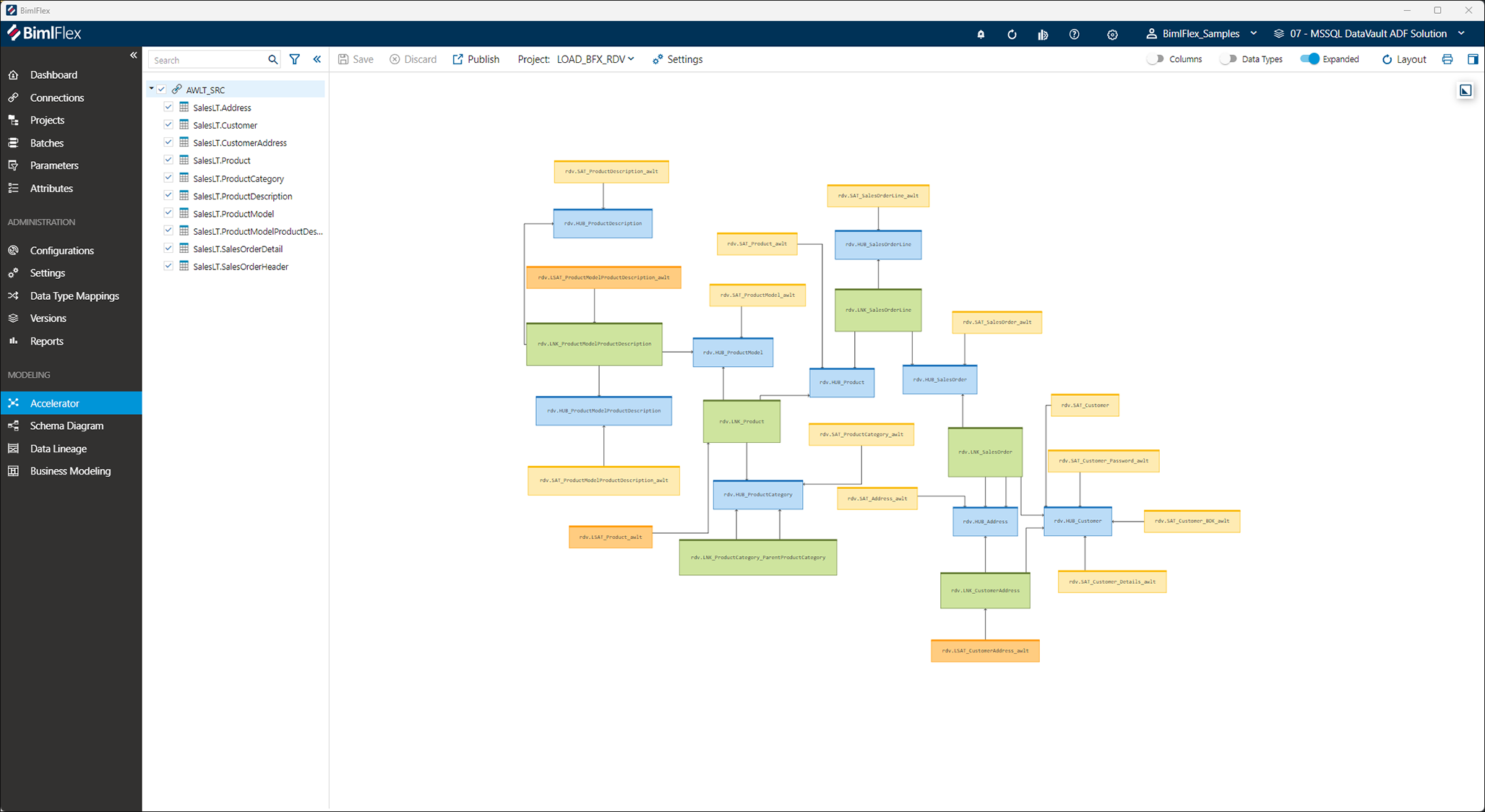
BimlFlex 的主要功能之一称为“加速器”。在将 BimlFlex 指向要从中集成数据的系统后,加速器会从导入的(源)数据结构中推断出初始数据模型,包括从数据源到目标模型的沿袭。这是 yFiles 的主要功能之一,因为它可以直接与建议的模型交互并对其进行调整以满足数据要求。在界面中,用户可以添加、修改或删除关系,并应用各种惯例来改变模型,以实现预期结果。结果是即时可见的,因此用户可以查看其定制的效果,并根据需要进行相应调整。
yFiles 提供无数的布局选项
yFiles 为 Varigence 提供了一种现代、快速且功能丰富的能力,可以以一种方便用户使用的方式实现多种关系和对象可视化。
使用 BimlFlex 数据解决方案自动化套件时,该软件将根据提供数据的系统中可用的元数据提供目标数据模型和谱系的第一个版本。用户可以直接与生成的对象(例如数据库表或关系)交互,并在从指定源加载到新目标结构时对数据需要解释的方式进行修改。
例如,可以通过上下文菜单修改建议的数据仓库表。这样,可以更改表的用途或定义,包括选择是否应将某些属性包含在代码生成中,或以不同的方式解释。这就是 BimlFlex 用户如何“调整”数据模型以满足预期的数据要求。
这也扩展到实现复杂的转换,这些转换被定义为源列和目标列之间映射的一部分。每个列映射都可以包含转换数据的逻辑,这在 yFiles 中表示为“边缘”,允许进行各种交互。然后使用此映射为目标基础架构生成本机代码。定义目标(数据)模型并使用它来正向设计相应的数据物流流程是 Varigence 产品用户花费时间最多的地方 - 因此在这一领域拥有丰富的经验是重中之重。
yFiles 源代码演示的使用对 Varigence 来说非常有价值。Sankey演示用于沿袭视图,以清晰显示列到不同目标的映射。列表节点演示用于创建表和列之间的关系,提供详细且易于理解的可视化效果。上下文菜单演示允许高效、直观的建模操作,例如拆分表和添加键。
可扩展性和新图表功能
Varigence 利用强大的 yFiles 图形可视化和布局库开发了一种创新的数据建模和集成解决方案。这种集成不仅提高了 Varigence数据管理平台的性能和可扩展性,而且还使新计划和功能能够无缝实施。yFiles 的加入为 Varigence 开辟了更多的可能性,使该公司能够更好地服务客户并满足快速发展的数据格局的需求。
